优化 FontAwesome 资源文件的体积
在前端项目中,跑 build 命令生成最终所需的资源文件时,nuxt 总会提示 FontAwesome 用到的 svg 字体文件大小超过了推荐值,甚是恼人。于是开始考虑着怎么才可以解决这个 WARNING。先看看用到的 FontAwesome 字体资源文件:

1. 移除不需要的字体文件
如果 Web 项目,只需要支持主流的浏览器,基本只保留 woff 格式的字体文件就足够了,可以在 caniuse 上查看具体的兼容性细节。
2. 优化 woff 文件体积和 css 文件
项目中用到的 FontAwesome 图标,可能只有十几个,但 woff 字体文件却把所有的图标文字都涵盖进来,引起不必要的资源引入;FontAwesome 的 css 文件同理。在搜索优化 FontAwesome 资源体积的文章时,看到有类似 fontello, icomoon 这样的项目,它们可以做到生成的 FontAwesome 字体文件只涵盖我们用到的图标,但他们都需要手动去选我们需要哪些图标,如果项目中新增了用到的 FontAwesome 图标,就需要再手动再去选择一次,也是麻烦。理想的解决办法应该是:写脚本自动找到用到的 FontAwesome 的图标,然后自动生成需要的 woff 文件和 css 文件。具体脚本实现步骤如下:
- 用 Python 历遍所有文件内容
- 对每个文件内容用正则找到所有 ‘fa-xx’ 的类:
re.findall(r"fa-[A-Za-z0-9-]+", file_content) - 把所有匹配的 FontAwesome css 类放到一个集合中,得到一个集合如:
fa_class_set = {'fa-adjust', 'fa-envelope', 'fa-plus', 'fa-trash-o', 'fa-times'} - 找到 font-awesome.css 文件位置,一般在:
node_modules/font-awesome/css/font-awesome.css - 解析 font-awesome.css 文件内容,找出项目中用到 css 类,把不用到的 css 类删掉,生成一个 FontAwesome css 子集的文件:
css_path = 'node_modules/font-awesome/css/font-awesome.css' css_subset_path = 'assets/css/font-awesome-subset.css' unicode_set = set() unicode_file = 'scripts/unicodes.txt' with open(css_path) as f: file_str = f.read() file_str = file_str.replace(',\n', ', ') matches = re.findall(r".fa-[a-z0-9-:{,.\s\n]+content: \"\\f[a-z0-9\"\n;\}]+", file_str) detect = {} for block in matches: if not getattr(detect, block, None): detect[block] = False if detect[block]: continue for fa_class in fa_class_set: if fa_class + ':' in block: detect[block] = True count = 0 for key, value in detect.items(): if value: count += 1 unicodes = re.findall(r"\"\\f[a-z0-9]+\"", key) for unicode in unicodes: unicode_set.add(f'U+{unicode[2:-1]}') else: file_str = file_str.replace(key, '') print(f'Finished extract {count} fa class....') - 上面的脚本还多做了一个事情,就是把 FontAwesome css 类所需要的图标对应的文字编码提取出来。因为假如项目中用到了 fa-plane 的图片,它需要的是 woff 字体文件里面,编码为
\F072的文字。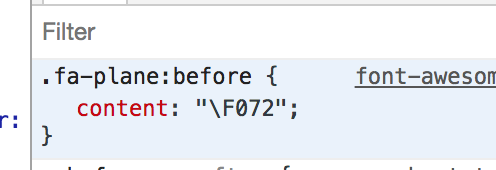
- 到这里,已经得到了一个 unicode 的集合,在
scripts/unicodes.txt里面,里面包含了项目需要的 FontAwesome 图标对应的 unicode,如:U+f002 U+f007 U+f009 U+f00c U+f00d U+f014 - 使用 fonttools 过滤掉没有用到的图标文字:
pyftsubset node_modules/font-awesome/fonts/fontawesome-webfont.woff --unicodes-file=scripts/unicodes.txt --output-file=assets/fontawesome-webfont.subset.woff
原来的 fontawesome-webfont.woff 文件体积,大小为 98 kB,项目中用到了 23 个左右的图标,经上述脚本处理后,得到一个大小为:7.67 kB 的字体文件;
原来的 font-awesome.css 文件,由于减少了字体文件的引入,需要手工编辑字体引入的配置,移除 woff 文件外的其他字体文件引入。 编辑后的体积大小大概为 34 kB,项目中用到了 23 个左右的图标,经上述脚本处理后,得到一个大小为:3 kB css 子集文件。
目标完成,神清气爽,Webpack 编译也更快了!